理解 Agent,首先要回答一个问题:为什么很多任务不能通过一次 LLM call 完成?
什么是 LLM call
LLM call 指的是:向模型发起一次请求,并接收一次结果。
从 API 角度看,它对应一次 request 和一次 response。例如:
const res = await client.responses.create({
model: "gpt-5",
input: "总结这段日志",
});这个来回过程就是一次 LLM call。
一次 call 通常包含:
- prompt 或 messages
- 当前上下文
- tool schemas
模型返回的结果通常是:
- 一段 text
- 一个
tool call
tool schema 和 tool call 的区别
两者可以类比为后端开发中的“函数定义”和“函数调用”:
tool schema类似function signature,描述可用工具的名称和参数结构tool call类似一次真正的函数调用,是模型给出的具体调用请求,例如调用哪个工具、传入什么参数
关键点在于:tool call 通常不是开发者随请求直接传给模型的,而是模型在 response 中生成的。
为什么 single call 不够
看一个例子:
修复一个陌生 Node.js repo 里的 failing test,直到 CI 通过
这个任务不是一次性的 input -> output,而是一个循环过程:
- 先做一个 action,比如运行测试
- 得到新的 observation,例如测试输出
- 根据这个 observation 做下一次 decision
- 再执行新的 action
- 重复,直到目标达成
关键在于:新的 observation 是执行动作之后才产生的。
例如,模型先输出“请运行测试”,测试结果只有在测试执行完成后才会出现。它不可能被同一次 LLM call 看到,因为那次 call 在模型返回时已经结束。
因此,问题不只是“复杂”,而是:
- 中途会产生新的信息
- 这些信息一开始并不在上下文里
- 下一步决策依赖这些新信息
这也是为什么“总结一段日志”常常一次 call 就够,而“运行测试 -> 读报错 -> 改代码 -> 重跑直到通过”通常不够。
Agent 为什么存在
Agent 存在,不是因为 LLM 不够聪明,而是因为很多真实任务本质上是一个闭环。
这个闭环可以写成:
decision -> action -> observation -> next decision
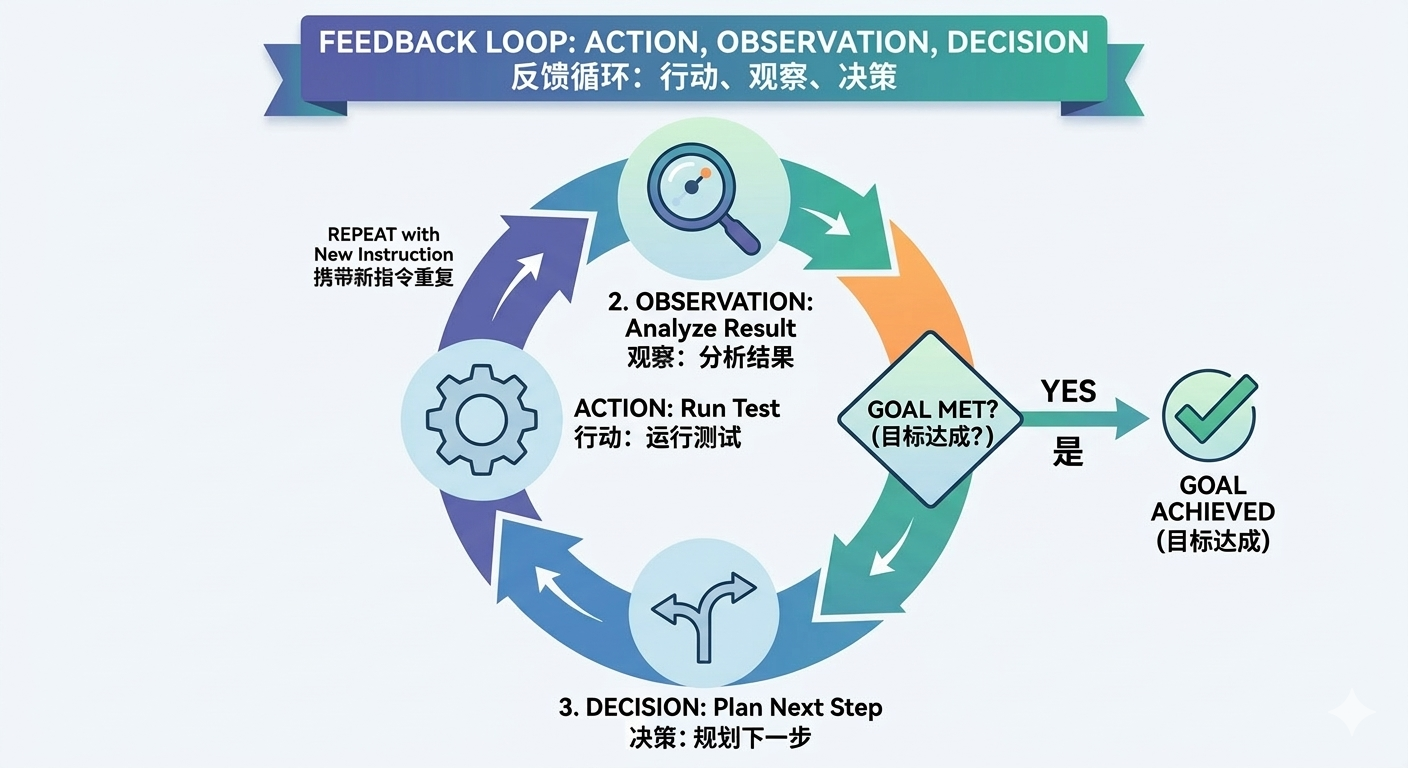
一旦任务需要这个闭环,single LLM call 就不够了,因为它无法在拿到新 observation 后继续推理。
总结
LLM call是一次 request/response,不是一个会自己持续运行的过程tool schema是工具定义,tool call是模型产出的具体调用- Agent 的核心不是“会调工具”,而是“能在 loop 中根据新 observation 持续决策”
- 需要 Agent 的任务,往往不是单次文本生成,而是多轮
action -> observation -> decision
后续
- Agent 的最小组成部分是什么?
- 一次真实 execution trace 到底长什么样?
- tool calling 的 API request/response 结构?
- planning、memory、failure handling 怎么落地?
- 什么情况下不该用 Agent?
- ReAct、tool-use、multi-agent 分别适合什么场景?
{kind=link}