前几天我重新整理了一次自己的 NetNewsWire.
本来只是想清理一下订阅,结果一看比我想的乱:本地和 iCloud 账户分叉了,分类也不统一,还有几个源已经很久不更新了。
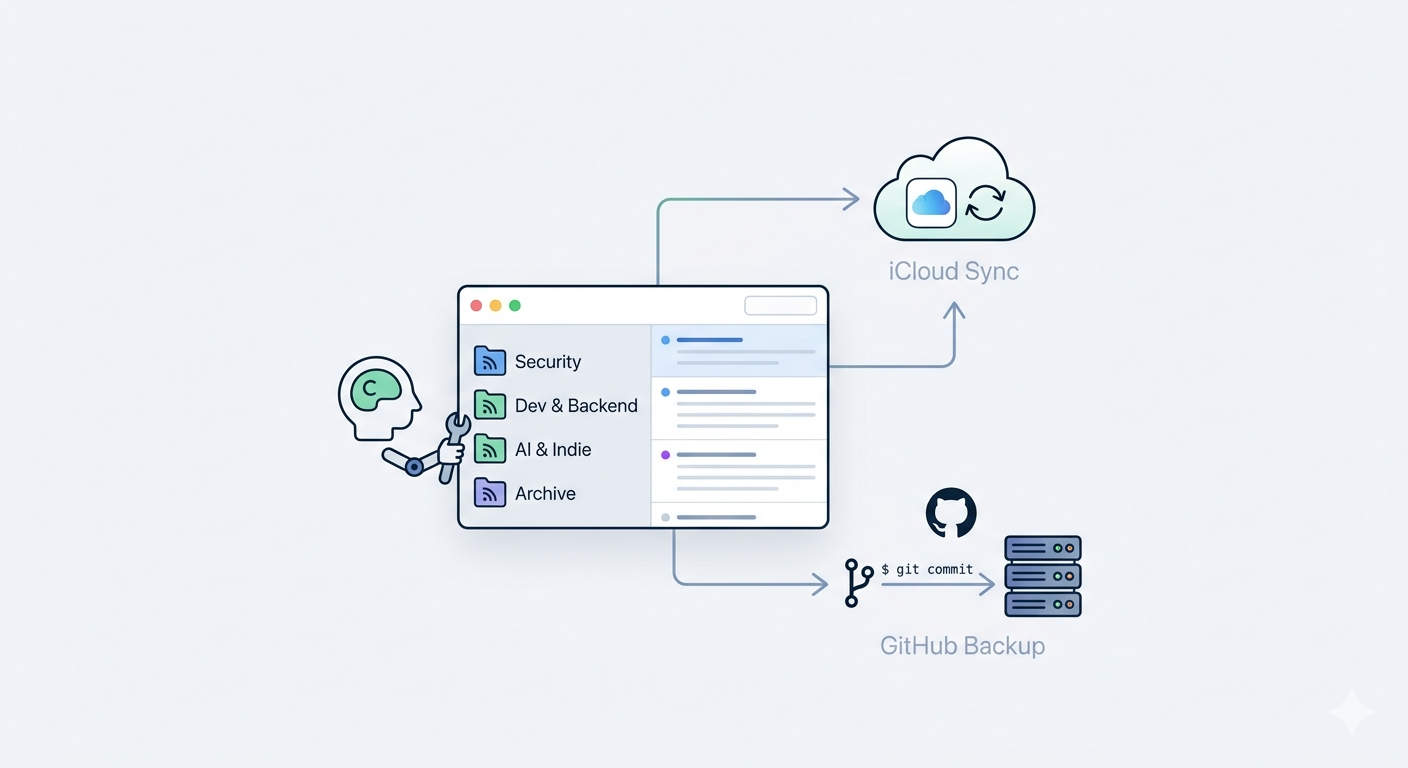
这次我直接让 Codex 帮我处理,用的模型是 gpt-5.4。体验很好。很多事情我自己也能做,但是比较碎,容易拖着不做;让它直接去看本地数据、判断问题、动手整理,会快很多。
最开始它先帮我看了一下本地数据,发现我实际上有两套账户:
On My MaciCloud
这两套账户已经不是镜像关系了。也就是说,我以为自己在同步,实际上只有一部分内容在同步,另一部分还在本地。
它先做了备份,然后把订阅合并到 iCloud,顺手把默认新增订阅、新增文件夹这些入口也都切到了 iCloud。这样以后就不会继续加到错误的地方。
之后又帮我重新整理了分类。这个过程其实比我想的更重要。订阅一乱,问题往往不在于“订阅太多”,而是它们都堆在一起,没有结构。
现在大概整理成了这几类:
SecurityFrontend & DesignGo & BackendEngineeringIndie & AI
我觉得这样已经够了。分类不是越细越好,能长期维持就行。
另外它还帮我看了各个订阅最近一次更新时间,把几个明显长期不更新的源移到了 Archive 里。
我不太想直接删。归档比较适合我,主列表会干净很多,但以后想翻也还能找到。
最后我又让它顺手把订阅配置接到了 GitHub 自动备份。
这一步也很好。同步解决的是“多设备一致”,备份解决的是“以后不慌”。现在订阅文件有变化时,会自动提交到我的 dotfiles 仓库。
总结
回头看,终于花时间整理了实际已经失去意义的“RSS 知识源”:
- 实际同步走
iCloud - 分类更清楚了
- 停更的源单独归档
- 订阅配置会自动备份到 GitHub
这次用的是 gpt-5.4。整体感受很好。
{kind=link}